paper : CLIP
StackGAN: Learning Transferable Visual Models From Natural Language Supervision
briefly explained in a few minutes
difficulty : 💛💛💛💛🖤
tags: vision transformer, contrastive learning, text-image bridging
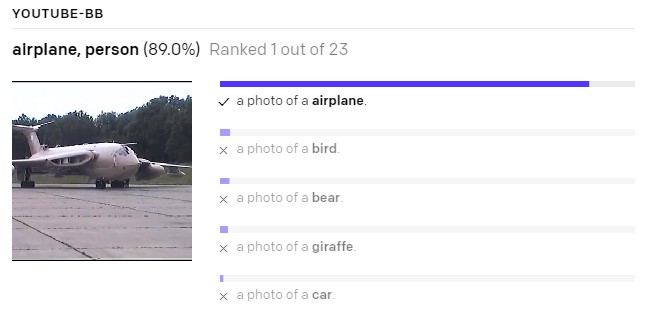
👀 Take a look
CLIP 是一個可以被使用在架接圖片與文本空間的模型,在該模型中有一個 text-encoder 與 image-encoder ,如果輸入的 image-text pair 是關聯的,則我們預期兩個 encoder 所產生的 embedding 應該會有一定的相關性,利用這樣的方法就可以產生許多的應用,比如配對、分類…。
📖 Prior knowledge
🚀 Motivation
CLIP 在許多領域內都有應用,且該模型創造了非常驚人的成果,由於圖片與自然語言是兩個本身就較難理解的範圍,現在必須想辦法將兩者連接起來更是有著數不清的障礙,這也導致以往的作法預測準確率低下,幾乎無法使用在現實生活中,而 CLIP 藉由 vision transformer 與 contrastive learning 的技巧克服了以前無法解決的問題,擁有與 GPT-2, GPT-3 相似的 zero shot 能力,且被訓練在他們提出的擁有 40 億對的資料集中,使得下游任務 (downstream task) 可以直接應用,而無須再經過對資料集的 fine-tune 。
🧠 Main Ideas
Abstract
在過去我們需要讓模型理解一張圖片,最好的方式的幫圖片加上標註,但其實這是有弊端的,因為僅僅只是標籤可能不足以形容一張圖片,如果能讓模型理解語言,將會是一個很大的突破。
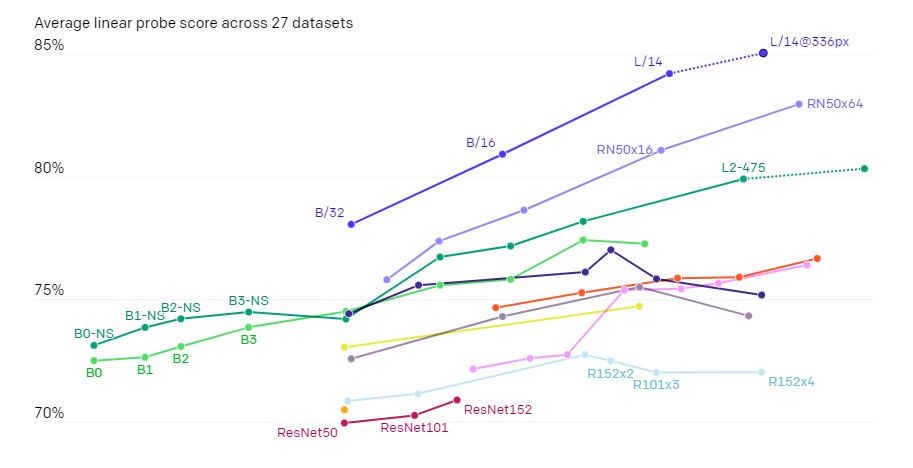
在這個部分, CLIP 在許多資料集上學習了共 40 億對的資料,達到了很好的成果,顯示出了 CLIP 的可擴充性以及訓練的效能,資料來源於許多資料集與網路資料 (包括30個已存在的資料集) 。
Architecture
前人主要在處理自然語言的複雜度,而由於 deep contextual representation learning 方法的進步,可以很好的利用這項資源,讓模型學習更豐富的資料,而非拘泥於減少計算量而讓模型效能降低
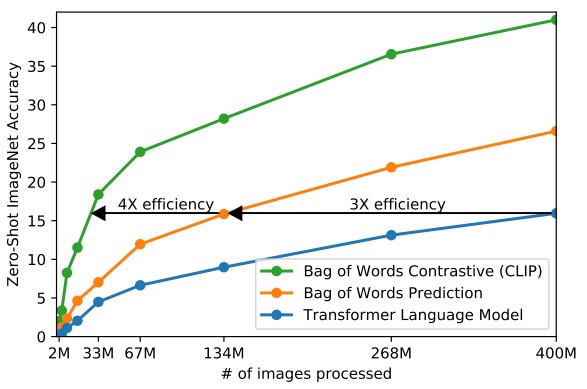
在 text encoder 的部分利用了 contrastive learning 的技巧,只需要更少的資料與訓練時間,就可以獲得更高的正確率。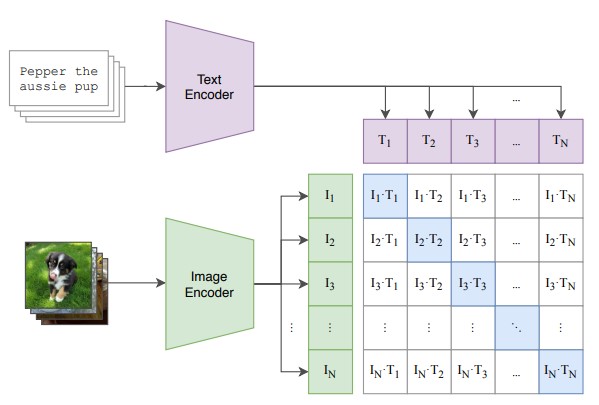
接著是 CLIP 的 pre-training ,中間的相乘表示 cosine similarity ,藍色的對角線代表 postive example 需要最大化,其他則是 negtive example 需要最小化。Prompt Engineering
現今常出現的資料集比起 image-text pair ,更多的大概還是標籤資料集,比如 Image-Net ,所以 prompt (前綴句) 就是需要研究的方面,不過在此之前要先提兩個要面對的問題。
第一個問題 : 一字多義
這個現象不會特別出現在某個資料集中,因為在製作資料集時會避免這種事情發生,比如使用不同的字詞去替換這些同義詞,但 CLIP 的訓練融合了多個資料集,於是這個問題必須要處理第二個問題 : 訓練資料不統一
在訓練資料集中部分資料是對於圖片有完整敘述的,但也有的形容只有一個字,這其實也會出現某種問題,而解決方法就是在前方加上一些前綴句,他們觀察到這樣的作法也會提高模型的效能
在這個章節最重要的就是 customizing the prompt ,比如針對寵物資料集可以是 A photo of a {label}, a type of pet. ,針對許多資料集以及內容制定好的前綴句,在提高模型效能上很有幫助。
👓 results