paper : StackGAN
StackGAN: Text to Photo-realistic Image Synthesis
with Stacked Generative Adversarial Networks
briefly explained in a few minutes
difficulty : 💛💛💛🖤🖤
tags: GAN, T2I

👀 Take a look
在 T2I 這個領域中最重要的事情就是生成逼真且符合文字輸入的圖片,而 StackGAN 是在該任務早期做的最好的模型之一,藉由堆疊的神經網路來生成更高解析度的圖片
📖 Prior knowledge
🚀 Motivation
由文本輸入來生成高品質圖片的問物在當時仍然是一個大問題,且生成符合描述圖片具有非常多實際上的應用。
要注意的是本篇是 2016 年的論文,在 2022 的現在,已經有非常多的生成模型試圖踏足 T2I 的領域,且取得了非常好的成就,這些都可能在未來進行介紹,不過 StackGAN 對此領域的未來造成了很大的影響,其中包括 AttnGAN、MirrorGAN、StackGAN-v2 等等生成模型,所以還是很重要的一個基礎
🧠 Main Ideas
Conditioning Augmentation
text embedding 通常是一個高維的向量,導致如果訓練資料不足可能導致 latent data 不連續,而這對於 generator 的訓練是有害的,所以他們提出了一種 data augmentation 的手法,主要的概念是先從 gaussian distribution 中 sample 一些 latent ,並且他的 mean 與 covariance 將會使用 text embedding 來決定,如此一來便提供了更多的訓練資料,並在 loss 中引入一個正則項使訓練過程更加平穩。Conditioning Augmentation 的使用有利於模型對文本到圖片之間進行連接。
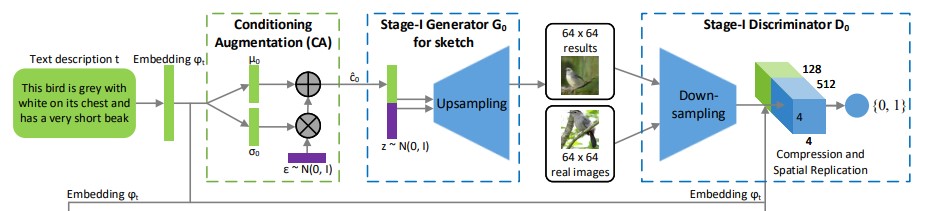
Stage-I GAN
如果在第一階段就嘗試生成最高解析度的圖片,常常會導致訓練過程不穩定,或是讓結果變差,所以有了 Stage-I 的出現。
在 StackGAN 的第一部分,首先藉由給定的文本描述,來決定繪製物件的初始模樣以及特定的顏色,並從 gaussian noise 中繪製圖片的背景樣式,來產生低解析度圖片
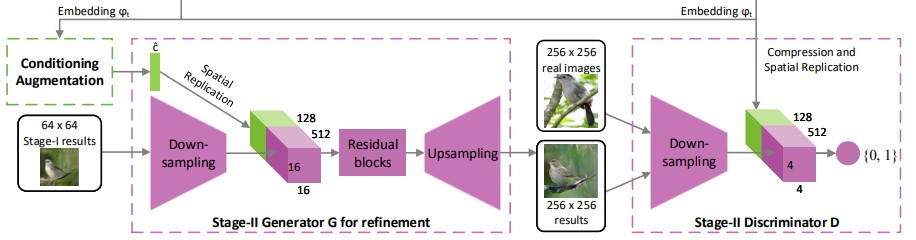
Stage-II GAN
將 Stage-I 所產生的圖片餵進 Stage-II 後,會再讀一次輸入進來的 text embedding ,來把圖片本來的細節加上去,生成高解析度圖片。
由 Stage-I 所產生圖片缺少了生動的物件,甚至有些物體可能是扭曲的,且由於 Stage-I 的能力不足,有些細節的文本資訊會被跳過,所以需要再重新生成這些細節
detail
相比許多模型只有一個 generator 、一個 discriminator ,StackGAN 使用了兩層的架構,在每個階段都有一對 GAN 的架構,且提出了一個獨特的,針對 text-to-image 的 data augmentation 方法。
👓 results




